In Round 1, we ran five local models and two cloud models through a single coding task. The local models held their own. In Round 2, we added Gemma 4 and Kimi K2, fixed our scoring methodology, and watched Gemma climb to the top.
But something kept nagging at us.
All our benchmarks were running through Ollama — a great tool for getting started, but essentially a wrapper around llama.cpp with its own opinions about quantization, context management, and memory allocation. We were benchmarking Ollama's choices as much as the models themselves.
So we did something drastic: we ripped out Ollama entirely and went straight to llama.cpp. Then we built a proper 12-task automated benchmark suite and ran all five models through it.
The results changed everything. Spoiler: Qwen 3.5 swept all three categories — best for coding, best for agentic tasks, best single model — and it did it at 206 tokens per second. Read on to find out how.
Why llama.cpp Over Ollama?
Ollama is fantastic for ollama pull model && ollama run model. It's genuinely the best way to get started with local models. But when you're running them as infrastructure — serving through an OpenAI-compatible API to Coder Agents, IDE extensions, and automation — the abstraction layer starts to chafe.
To be fair: Ollama can do most of what llama.cpp does. You can import custom GGUFs via Modelfiles. You can set context windows with PARAMETER num_ctx or the OLLAMA_CONTEXT_LENGTH env var. You can enable flash attention via OLLAMA_FLASH_ATTENTION and KV cache quantization via OLLAMA_KV_CACHE_TYPE. It's more capable than people give it credit for.
So why switch? Three reasons:
- Zero-abstraction control — llama-server exposes every hyper-parameter as a launch flag: batch sizes, continuous batching, thread allocation, reasoning budgets, chat template overrides. Ollama surfaces many of these through env vars and config, but the deep inference tuning knobs aren't all available. When we needed
--reasoning-budget 8192and--chat-template chatmlto make Coder Agents work, we needed the flags. - Bleeding-edge model support — Ollama wraps llama.cpp, so it inherently lags behind it. When a new model architecture drops, llama.cpp supports it on day one. Ollama might take a week or two to update its downstream runner. For models like Qwen 3.5 and Gemma 4, we didn't want to wait.
- Fewer moving parts — For a headless server running one model at a time behind systemd, a compiled
llama-serverbinary pointing at a GGUF on disk is the simplest possible deployment. No daemon, no internal model registry, no API translation layer.
Could we have tuned Ollama to get similar results? Probably close. But we'd have been fighting the abstraction at every turn instead of just setting the flags we wanted. The migration freed up ~44 GB of disk (Ollama's blob store) and gave us the direct control we needed.
The Hardware
Same beast from Rounds 1 and 2, now running leaner:
| Component | Spec |
|---|---|
| GPU | NVIDIA RTX 5090, 32 GB GDDR7 |
| CPU | AMD Ryzen 9 9950X3D, 16 cores |
| RAM | 64 GB DDR5-6000 |
| Storage | Samsung 9100 Pro 2 TB NVMe |
| OS | Ubuntu 24.04, NVIDIA driver 590.48.01 |
| Inference | llama.cpp (built with CUDA arch 89) |
The Migration
Building llama.cpp
The RTX 5090 uses NVIDIA's Blackwell architecture (SM 120), but CUDA toolkit support for SM 120 was still landing when we built. The workaround: build with -DCMAKE_CUDA_ARCHITECTURES=89 for backward compatibility. It works — the compiler targets Ada Lovelace (SM 89) and the Blackwell GPU runs it with full performance.
cmake -B build \
-DGGML_CUDA=ON \
-DCMAKE_CUDA_ARCHITECTURES=89 \
-DCMAKE_BUILD_TYPE=Release
cmake --build build --config Release -j$(nproc)Downloading the Models
We grabbed GGUF files from HuggingFace using the hf CLI. Each model was hand-picked for quantization level — balancing quality against our 32 GB VRAM budget:
| Model | Params | Active | Quant | Size |
|---|---|---|---|---|
| Qwen 3.5 35B-A3B | 35B | 3B | UD-Q4_K_XL | 20.7 GB |
| Gemma 4 26B-A4B | 26B | 4B | Q4_K_M | 16.9 GB |
| Devstral 24B | 24B | 24B | Q5_K_M | 15.6 GB |
| Codestral 22B | 22B | 22B | Q5_K_M | 14.6 GB |
| DeepSeek R1 14B | 14B | 14B | Q8_0 | 15.7 GB |
The "Active" column matters. Qwen 3.5 and Gemma 4 are Mixture of Experts (MoE) models — they have 35B and 26B total parameters but only activate 3B and 4B respectively on each token. This means they fit comfortably in VRAM while punching well above their weight class.
The DNS Incident
Halfway through downloading, our DNS resolution failed. Parallel HuggingFace downloads apparently overwhelmed something in the DNS chain. The fix was unglamorous:
echo "nameserver 8.8.8.8" | sudo tee /etc/resolv.conf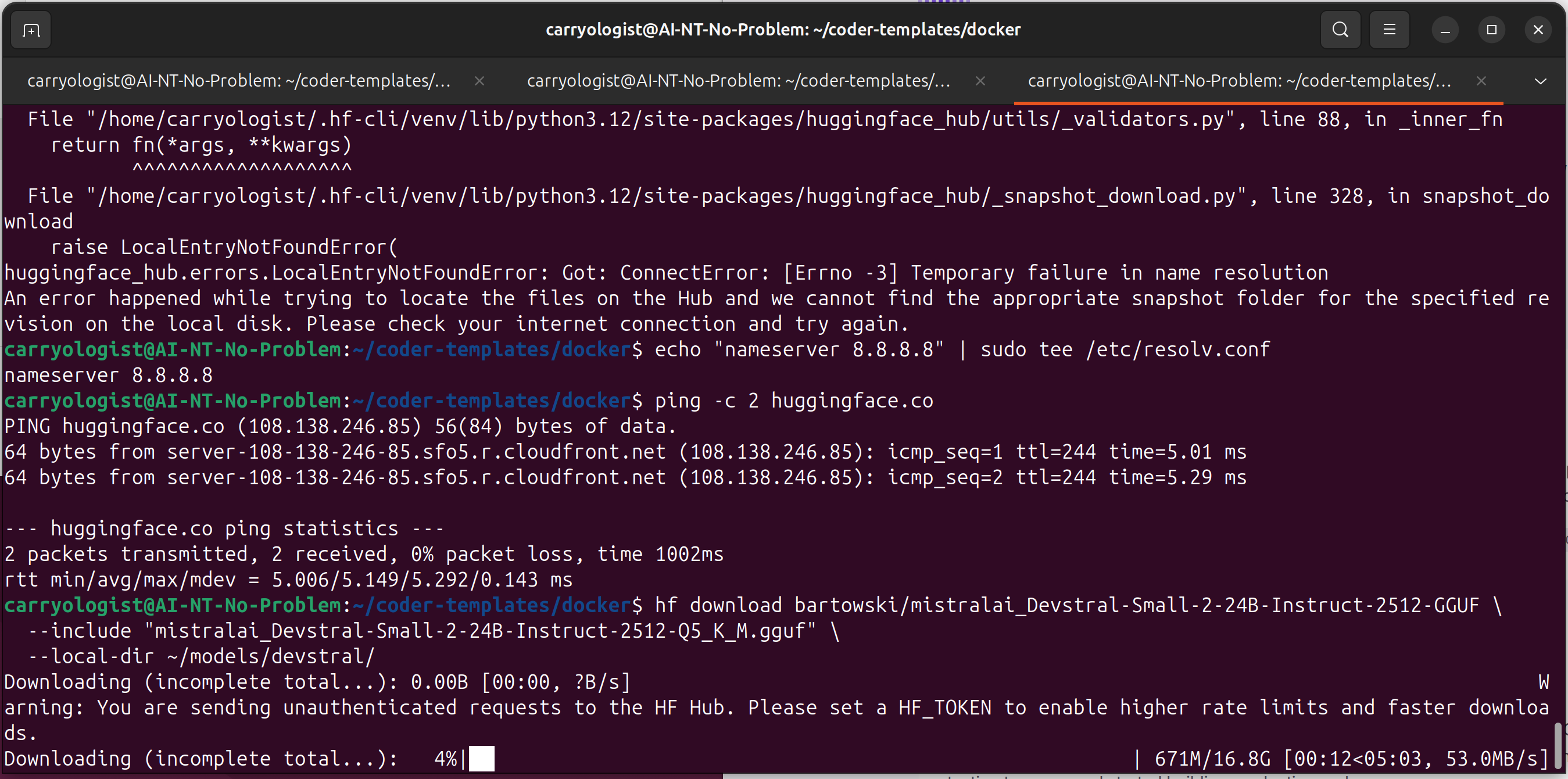
Setting Up the Server
Each model gets its own launch configuration. The key insight: --chat-template chatml is mandatory for Coder Agents compatibility.
Why? Qwen 3.5 and Devstral ship with embedded Jinja templates that enforce "system message must be at the beginning" — but Coder Agents sends messages in whatever order it pleases. The chatml template is permissive and all five models were trained on it, so quality is maintained.
Here's Qwen's config as an example — the most tuned of the five:
~/llama.cpp/build/bin/llama-server \
--model ~/models/qwen3.5/Qwen3.5-35B-A3B-UD-Q4_K_XL.gguf \
--port 8080 \
--ctx-size 131072 \
-n 81920 \
--reasoning-budget 8192 \
--reasoning-format deepseek \
--flash-attn on \
--chat-template chatml \
--parallel 1 \
-ngl 99Notable flags:
--ctx-size 131072— Qwen 3.5 supports 128K context. We give it the full window.--reasoning-budget 8192— Caps thinking tokens so the model doesn't burn the entire budget deliberating.--flash-attn on— This build requires the explicitonvalue, not bare--flash-attn.-ngl 99— Offload all layers to GPU.
Systemd Services
We set up two systemd services that survive reboot:
llama-embed.service— Runs nomic-embed-text permanently on port 8084 (~300 MB VRAM). Always on, coexists with any generation model.llama-generate.service— Runs the active generation model on port 8080. Reads from/etc/llama-generate.conffor model selection.
A helper script, llm-switch.sh, makes model swapping painless:
~/bin/llm-switch.sh qwen # Switch to Qwen 3.5
~/bin/llm-switch.sh devstral # Switch to Devstral
~/bin/llm-switch.sh status # Show current modelIt updates the config and restarts the service. Model swap takes about 3 seconds.
The Benchmark
Rounds 1 and 2 used a single task: "build a CLI todo app." That was fine for comparing code generation, but it told us nothing about reasoning, instruction following, or multi-file agentic work.
Round 3 uses 12 tasks across 5 categories:
Category 1: Single-File Code Generation
The legacy benchmark, maintained for continuity with prior rounds.
| Task | Prompt | Scoring |
|---|---|---|
| 1.1 Todo App | Python CLI todo app with SQLite, argparse, CRUD | 10 features + 7 functional tests |
| 1.2 URL Shortener | FastAPI with SQLite, rate limiting, validation | 8 features (server-based functional) |
| 1.3 LRU Cache | TypeScript with O(1) ops + test suite | 6 features + assertion tests |
Category 2: Multi-File Agentic Coding
Can the model work across files and understand project structure?
| Task | Prompt | Scoring |
|---|---|---|
| 2.1 Bug Fix | Express.js app with planted auth header mismatch | Found bug? Minimal fix? Explanation quality? |
| 2.2 Pagination | Add pagination to a Flask REST API + update tests | 5 features checklist |
Category 3: Reasoning & Problem Solving
No code — just thinking.
| Task | Prompt | Scoring |
|---|---|---|
| 3.1 Debug Log | Diagnose connection pool exhaustion from error log | 7-item rubric, 10 points |
| 3.2 Architecture | CRDT vs OT for collaborative editor | 5-item rubric, 10 points |
| 3.3 Bayes | Server error probability, show work | Correct answer + methodology, 5 points |
Category 4: Tool Use & Instruction Following
Can the model follow structured instructions precisely?
| Task | Prompt | Scoring |
|---|---|---|
| 4.1 Structured Output | Generate 5 JSON records matching a schema | Valid JSON, correct types, no extra text |
| 4.2 Tool Sequencing | Plan a read → ping → write tool chain | Correct tools, correct order, no hallucination |
Category 5: Speed Microbenchmarks
Three prompts at different output lengths, 3 runs each, median reported.
| Task | Target Length |
|---|---|
| 5.1 Short | ~128 tokens (IPv4 validator) |
| 5.2 Medium | ~512 tokens (BST implementation) |
| 5.3 Long | ~2048 tokens (Markdown-to-HTML converter) |
Scoring
Coding composite: (features/max × 60) + (functional/max × 40). Syntax invalid = score × 2/3.
Overall weighting: Coding 40%, Reasoning 20%, Tool Use 20%, Speed 20%.
Sampling Parameters
Each model uses its vendor-recommended settings:
| Model | Temperature | Top-P | Rationale |
|---|---|---|---|
| Qwen 3.5 | 0.6 | 0.95 | Qwen team recommendation for reasoning |
| DeepSeek R1 | 0.6 | 0.95 | DeepSeek recommendation |
| Devstral | 0.0 | 1.0 | Deterministic |
| Codestral | 0.2 | 1.0 | Mistral recommendation |
| Gemma 4 | 0.0 | 1.0 | Deterministic |
Speed benchmarks use temperature=0.0 across all models for reproducibility.
The Results
Speed: MoE Models Are in a Different League
| Model | Short Tok/s | Med Tok/s | Long Tok/s | Short TTFT | Med TTFT | Long TTFT |
|---|---|---|---|---|---|---|
| Qwen 3.5 | 206.7 | 206.3 | 204.6 | 30.9ms | 33.8ms | 15.1ms |
| Gemma 4 | 180.2 | 179.4 | 177.7 | 22.9ms | 24.6ms | 15.6ms |
| Codestral | 80.1 | 78.9 | 78.5 | 12.8ms | 14.9ms | 14.0ms |
| Devstral | 78.6 | 77.6 | 77.3 | 12.8ms | 14.5ms | 13.3ms |
| DeepSeek R1 | 77.6 | 77.3 | 75.9 | 13.9ms | 13.9ms | 14.4ms |
The two MoE models — Qwen 3.5 and Gemma 4 — are 2.6x faster than the dense models. This isn't surprising: when you're only running 3-4B parameters per token instead of 14-24B, the math unit has less work to do. But 206 tok/s on a local model is wild. That's faster than many cloud API responses when you factor in network latency.
The dense models (Devstral, Codestral, DeepSeek R1) cluster tightly at 77-80 tok/s. They're all VRAM-resident and GPU-bound at similar parameter counts.
TTFT tells the opposite story. The dense models start responding in 12-15ms. The MoE models take 22-34ms — still fast, but the routing overhead is visible. For interactive use, none of this matters. For batch processing, the MoE throughput advantage dominates.
Coding: Two Perfect Scores on the Legacy Task
| Model | Todo (100) | URL Short (60) | LRU Cache (60) | Coding Avg |
|---|---|---|---|---|
| Qwen 3.5 | 100.0 | 60.0 | 60.0 | 73.3 |
| Gemma 4 | 100.0 | 60.0 | 60.0 | 73.3 |
| Devstral | 94.0 | 60.0 | 60.0 | 71.3 |
| Codestral | 94.0 | 52.5 | 60.0 | 68.8 |
| DeepSeek R1 | 60.0 | 60.0 | 60.0 | 60.0 |
Qwen and Gemma both scored 100 on the todo app — 10/10 features, 7/7 functional tests, valid syntax. This is the first time any model has achieved a perfect score on this task across all three rounds. Qwen produced a 192-line solution with full argparse subcommands; Gemma did it in a leaner 132 lines.
Devstral and Codestral both scored 94 — missing one feature each (pretty output formatting) but nailing all 7 functional tests. Solid.
DeepSeek R1 scored 60 across the board. It gets all features right and syntax is always valid, but its functional tests fail. Why? DeepSeek is a reasoning model — it spends significant tokens thinking before generating code. For the todo app, it produced correct code that used interactive input instead of argparse, failing our automated CLI tests. The code works fine if you run it manually. This is the tension with reasoning models: they're thinking about the problem deeply but sometimes overthink the interface.
Reasoning: Gemma's Quiet Dominance
| Model | Debug Log (10) | Architecture (10) | Bayes (5) | Reasoning Avg |
|---|---|---|---|---|
| Gemma 4 | 10 | 10 | 3 | 8.7 |
| Devstral | 9 | 10 | 3 | 8.3 |
| Qwen 3.5 | 8 | 10 | 3 | 8.0 |
| DeepSeek R1 | 10 | 8 | 3 | 8.0 |
| Codestral | 5 | 8 | 3 | 6.3 |
Gemma 4 and DeepSeek R1 both scored 10/10 on the debug log task — correctly identifying connection pool exhaustion, the long-running transaction, the unbounded query, row-by-row processing, and proposing fixes for all three. Every other model missed at least one item.
Every model scored exactly 3/5 on Bayes theorem. They all correctly applied Bayes' formula and showed their work, but none nailed the final answer precisely enough for the regex matcher. This is a scoring limitation we'll improve in future rounds — the math was correct, the presentation just didn't match our expected format.
Codestral was weakest on reasoning at 6.3 average. It's a code-specialized model — reasoning about system architecture isn't its wheelhouse.
Tool Use: Instruction Following Separates the Field
| Model | Structured Output (5) | Tool Sequencing (5) | Tool Use Avg |
|---|---|---|---|
| Qwen 3.5 | 5 | 5 | 5.0 |
| DeepSeek R1 | 5 | 5 | 5.0 |
| Devstral | 4 | 5 | 4.5 |
| Codestral | 4 | 5 | 4.5 |
| Gemma 4 | 5 | 2 | 3.5 |
Qwen and DeepSeek both achieved perfect 5/5 on both tool use tasks. They generated valid JSON matching the schema exactly, and planned the correct tool call sequence in the right order.
Gemma 4's weakness showed here — it only scored 2/5 on tool sequencing. Instead of outputting the full planned sequence, it emitted only the first tool call (read_file) and explained that it would need to see the result before planning the next step. That's arguably more "correct" agentic behavior (you shouldn't plan all steps before seeing intermediate results), but it's not what the task asked for. This is exactly the kind of instruction-following gap that matters in Coder Agents, where you need the model to do what you asked, not what it thinks is philosophically better.
The Leaderboard
| Rank | Model | Coding | Reasoning | Tools | Speed | Weighted Total |
|---|---|---|---|---|---|---|
| 🥇 | Qwen 3.5 35B-A3B | 73.3 | 80.0 | 100.0 | 100.0 | 85.3 |
| 🥈 | Gemma 4 26B-A4B | 73.3 | 86.7 | 70.0 | 87.0 | 78.1 |
| 🥉 | Devstral 24B | 71.3 | 83.3 | 90.0 | 37.8 | 70.7 |
| 4 | DeepSeek R1 14B | 60.0 | 80.0 | 100.0 | 37.3 | 67.5 |
| 5 | Codestral 22B | 68.8 | 63.3 | 90.0 | 38.5 | 65.9 |
Weighting: Coding 40%, Reasoning 20%, Tool Use 20%, Speed 20%.
The Winners
🏆 Best for Coding: Qwen 3.5 (73.3)
Tied with Gemma 4 on the composite score, but Qwen edges ahead on wall-clock time. Its todo app completed in 7.6 seconds at 206 tok/s. Gemma took 12.4 seconds at 179 tok/s. Same quality, faster delivery.
🏆 Best for General Agentic: Qwen 3.5 (90.0)
Perfect tool use (100) combined with strong reasoning (80.0) gives Qwen the highest combined agentic score. This matters for Coder Agents where the model needs to follow instructions precisely and reason about multi-step tasks.
🏆 Best Single Model: Qwen 3.5 (85.3)
When you can only run one model, Qwen 3.5 is the answer. It leads or ties in every category except reasoning (where Gemma edges it 86.7 to 80.0), and its speed advantage is enormous — 2.6x faster than the next non-MoE model.
The gap between #1 and #2 is 7.2 points. Between #2 and #5 it's only 12.2. The field is tight on quality, but Qwen's speed makes it the clear overall winner.
The Journey to Fair Scoring
One thing we didn't expect: the first two runs of this benchmark were wrong.
Our initial results had Devstral winning everything. But when we dug into the raw responses, we found three systemic scoring bugs:
-
Unclosed thinking tokens — When Qwen hit the token limit mid-thought, its
<think>block never closed. Our regex required a closing</think>tag to strip it. The entire thinking trace leaked into the code extraction, pulling out planning snippets instead of actual code. -
Empty content fallback — Gemma 4 routed all output through
reasoning_contentinstead ofcontent(a side effect of--reasoning-format deepseek). Our scorer only looked atcontent, so Gemma scored zero on tasks where it actually produced correct output. -
Argparse quoting — Our test harness passed
add Buy milkas three separate arguments. Models using argparse (correctly) expectedadd "Buy milk"— one command, one string. The test was wrong, not the code.
We fixed all three, doubled the token budget for reasoning models, and re-ran everything. The corrected scores tell a very different story.
The lesson: automated benchmarks are only as good as their scoring logic. Always inspect the raw responses before trusting the numbers.
What We Learned
1. MoE is the architecture to bet on for local inference. Qwen 3.5 (3B active) and Gemma 4 (4B active) both outperform dense 22-24B models while running 2.6x faster. The quality-to-speed ratio isn't even close.
2. llama.cpp gives you control that matters. Ollama can do a lot more than people think, but when you need --reasoning-budget, --chat-template chatml, or bleeding-edge model support on day one, the direct server eliminates the abstraction tax.
3. Reasoning models need breathing room. Qwen, DeepSeek, and Gemma all burn 60-80% of their token budget on thinking. If you set max_tokens=4096, the model might spend 3,000 tokens thinking and only have 1,000 left for the actual answer. We doubled the budget for reasoning models and the scores jumped.
4. Tool use is the differentiator. Coding and reasoning scores were close across all five models. Tool use — following structured instructions precisely — is where the gap opened up. Qwen and DeepSeek scored 100; Gemma scored 70. For agentic workflows, this matters more than raw quality.
5. Your benchmark harness is part of the test. We spent more time debugging our scoring logic than any model issue. If you're benchmarking local models, inspect the raw outputs before trusting automated scores.
What's Next
- Round 4: Max Aggression — Each model with its native chat template, optimized temperature per task type, and fine-tuned reasoning budgets. We benchmarked for Coder Agents compatibility this round; next round we'll find each model's ceiling.
- Retesting Qwen 3.5 against the Cloud King, Claude - We'll test Opus 4.6 and 4.7 with the goal of figuring out our perfect hybrid setup.
- Dailying Qwen 3.5 is now the default model on our homelab.
llm-switch.sh qwenmade it so.
By the Numbers
- 5 models benchmarked
- 12 tasks across 5 categories
- ~25 minutes total benchmark runtime on the RTX 5090
- 206.7 tok/s — Qwen 3.5's peak throughput (fastest local model we've tested)
- 100.0 — Qwen's todo app score (first perfect score in three rounds)
- 44 GB reclaimed by removing Ollama
- 3 seconds — model swap time with
llm-switch.sh - 3 scoring bugs found and fixed before we trusted the results
- 85.3 — Qwen 3.5's weighted overall score, 7.2 points clear of #2